── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4.9000 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 4.0.0 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library("gridExtra")
Attaching package: 'gridExtra'
The following object is masked from 'package:dplyr':
combine
library("Sleuth3")
Logistic regression can be used when your response variable is a count with a known maximum. Similar to regression, explanatory variables can be continuous, categorical, or both. Here we will consider models up to two explanatory variables.
When there are two (or more) explanatory variables, we can consider a main effects model or models with interactions. The main effects model will result in parallel lines or line segments while the interaction model will result in more flexible lines or line segments. These lines will be straight when plotting the response variable on a logistic axis, although we will rarely do so since the interpretation is very difficult.
42.1 Model
Let \(Y_i\) be the number of successes out of \(n_i\) attempts. The logistic regression model assumes Assume \[
Y_i \stackrel{ind}{\sim} Bin(n_i, p_i), \quad
\mbox{logit}(p_i) = \log\left(\frac{p_i}{1-p_i} \right) =
\beta_0 + \beta_1X_{i,1} + \cdots + \beta_{p} X_{i,p}
\] where \(Bin\) designates a binomial random variable and, for observation \(i\),
\(p_i\) is the probability of success
\(p_i/(1-p_i)\) is the odds, and
\(\log[p_i/(1-p_i)]\) is the log-odds.
A common special case of this model is when \(n_i=1\) for all \(i\). In this situation, the response is binary since \(Y_i\) can only be 0 or 1.
42.1.1 Assumptions
The assumptions in a logistic regression are
observations are independent
observations have a binomial distribution (each with its own mean)
and
the relationship between the probability of success and the explanatory variables is through the \(\mbox{logit}\) function.
Later we will need the inverse of the logit function. We will call this expit.
# Inverse of logit functionexpit <-function(x) {1/ (1+exp(-x))}
We will create another function to round probabilities to 2 decimal places
# Function to keep a fixed number of decimal placeskeep_decimals <-function(x, decimals =2) {# Check if input is numericif (!is.numeric(x)) stop("Input must be numeric")# Format with fixed decimal places formatted <-format(round(x, decimals), nsmall = decimals)return(formatted)}
42.1.2 Interpretation
When no interactions are in the model, an exponentiated regression coefficient is the multiplicative effect on the odds for a 1 unit change in the explanatory variable when all other explanatory variables are help constant. Mathematically, we can see this through \[
\frac{p'}{1-p'} = e^{\beta_j} \times \frac{p}{1-p}
\] where \(p\) is the probability when \(X_j = x\) and \(p'\) is the probability when \(X_j = x+1\). If the \(X_j\) are categorical, then this is the effect of being in the category versus the reference category.
If \(\beta_j\) is positive, then \(e^{\beta_j} > 1\) and the probability goes up. If \(\beta_j\) is negative, then \(e^{\beta_j} < 0\) and the probability goes down.
42.1.3 Inference
Individual regression coefficients are evaluated using \(z\)-statistics derived from the Central Limit Theorem and data asymptotics. This approach is known as a Wald test. Similarly confidence intervals and prediction intervals are constructed using the same assumptions and are thus referred to as Wald intervals.
Collections of regression coefficients are evaluated with drop-in-deviance where the residual deviances from the model with and without these terms in the model are compared with a \(\chi^2\)-test.
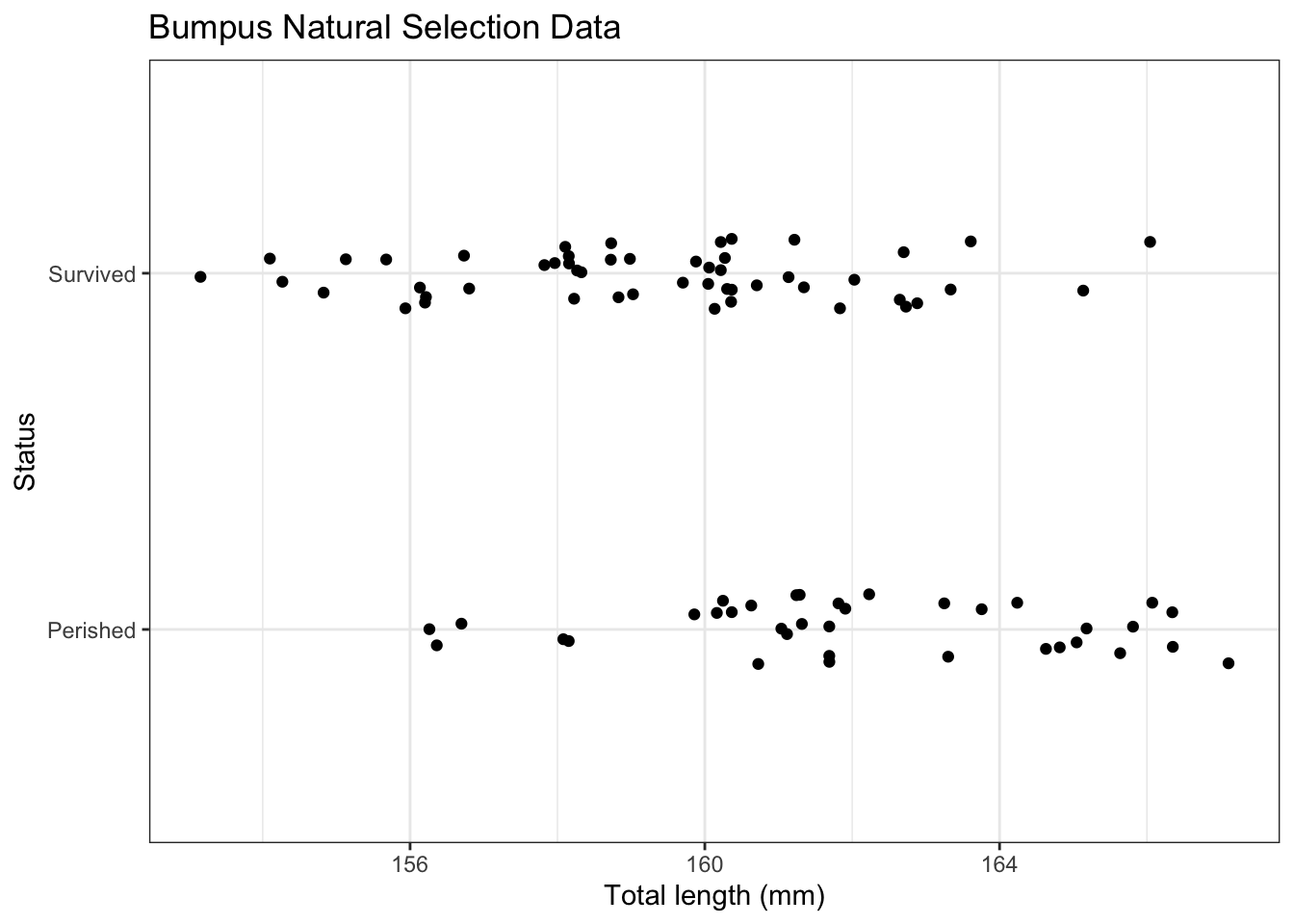
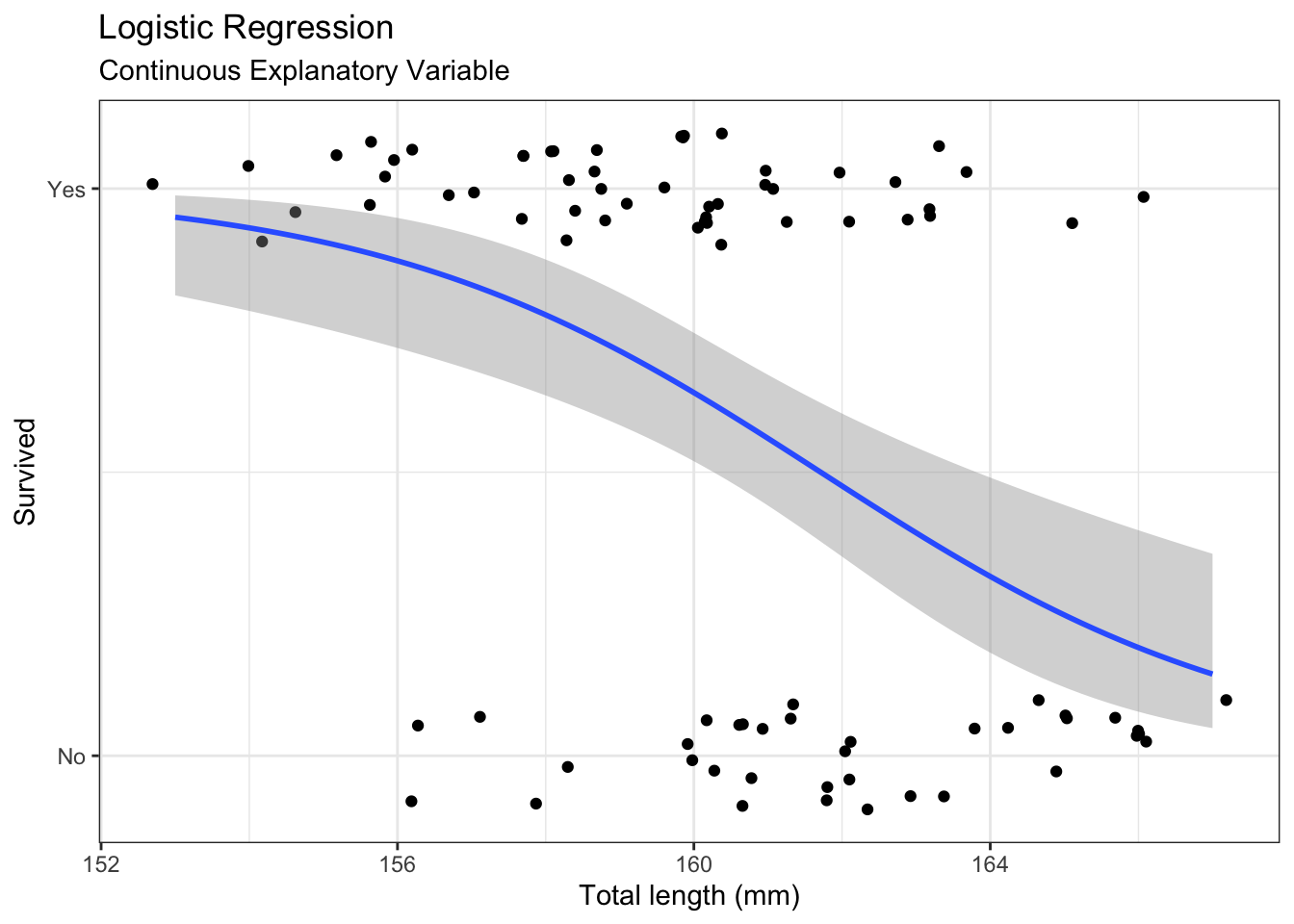
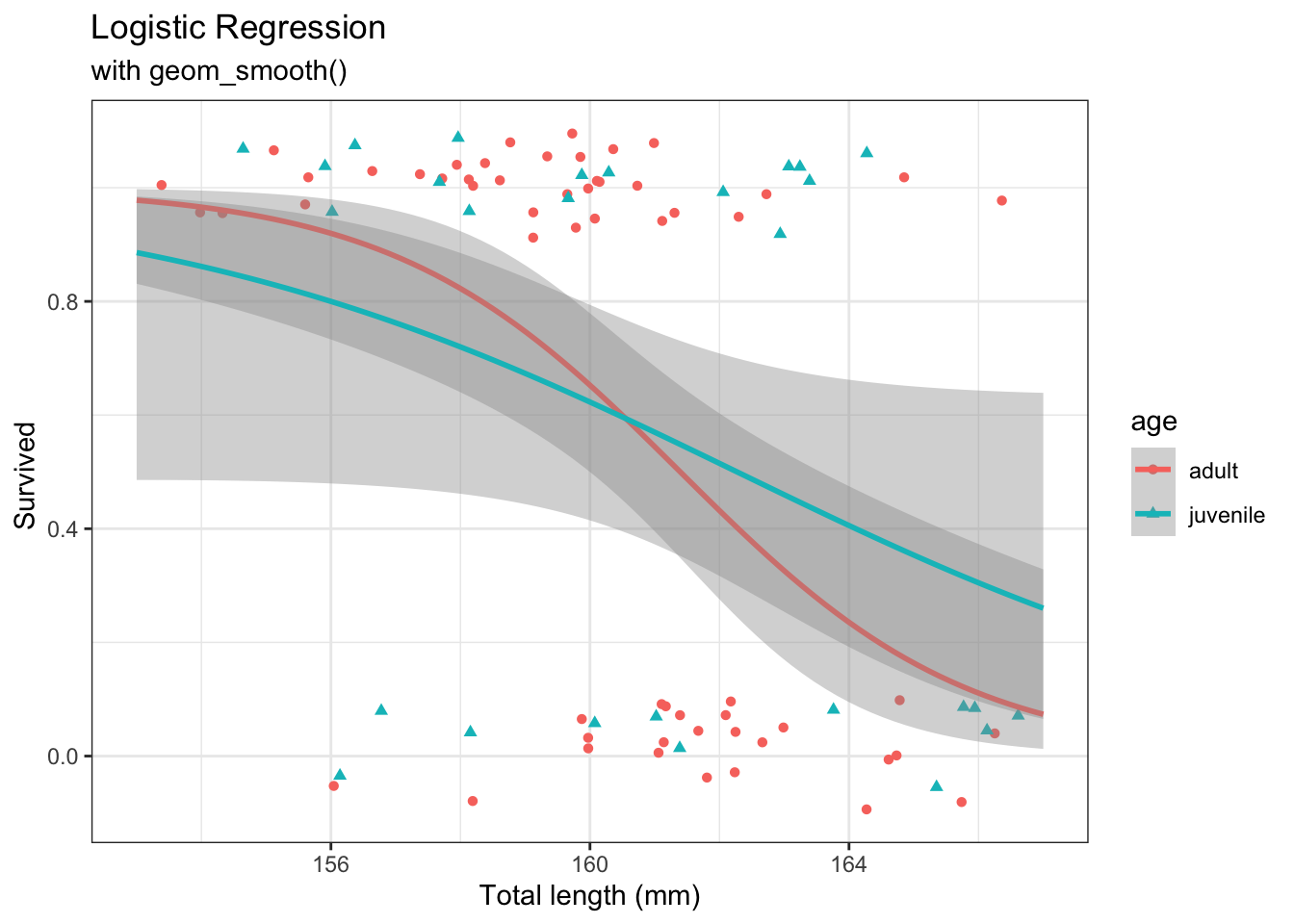
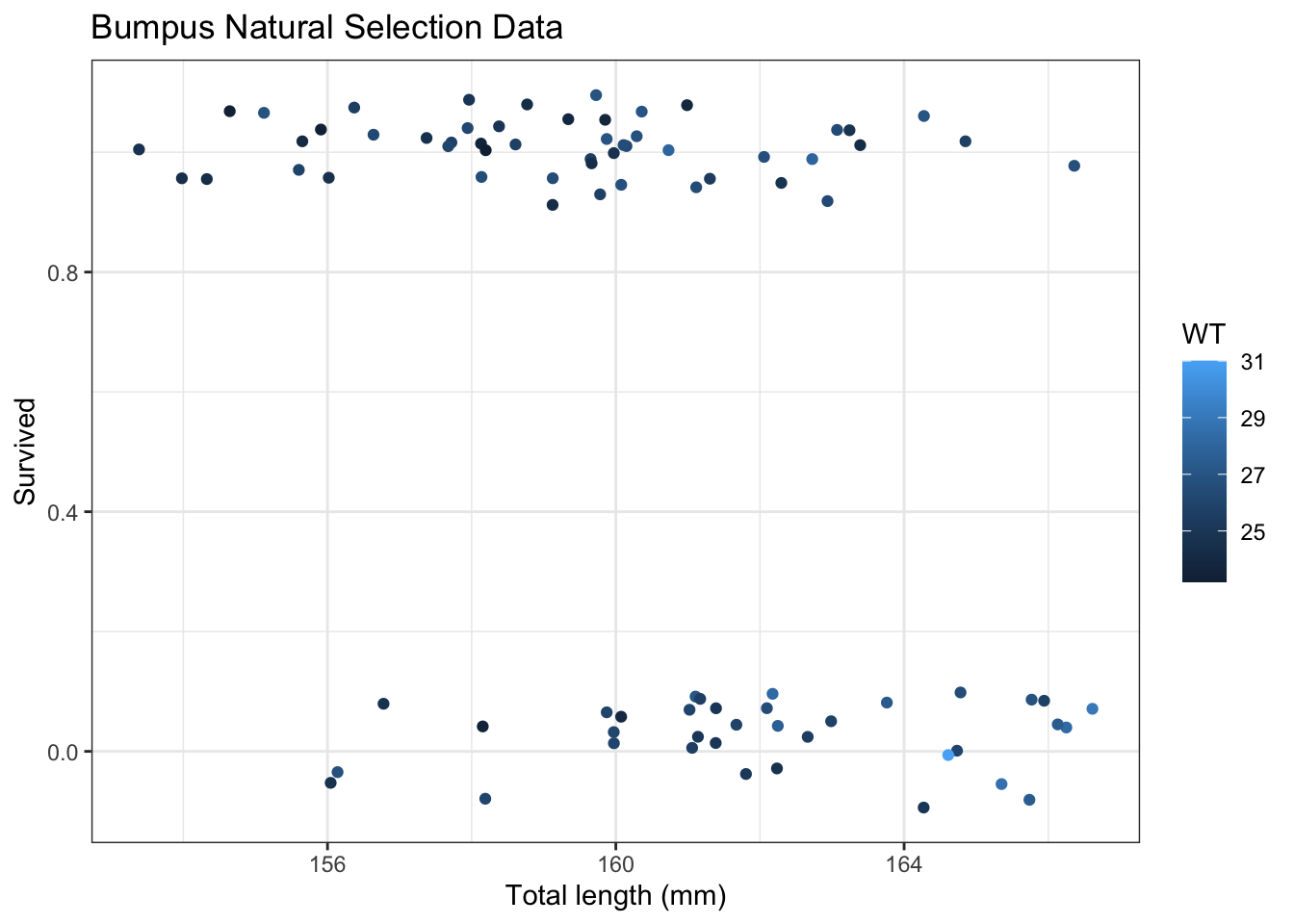
42.2 Continuous variable
First we will consider simple logistic regression where there is a single continuous explanatory variable.
`summarise()` has grouped output by 'TL'. You can override using the `.groups`
argument.
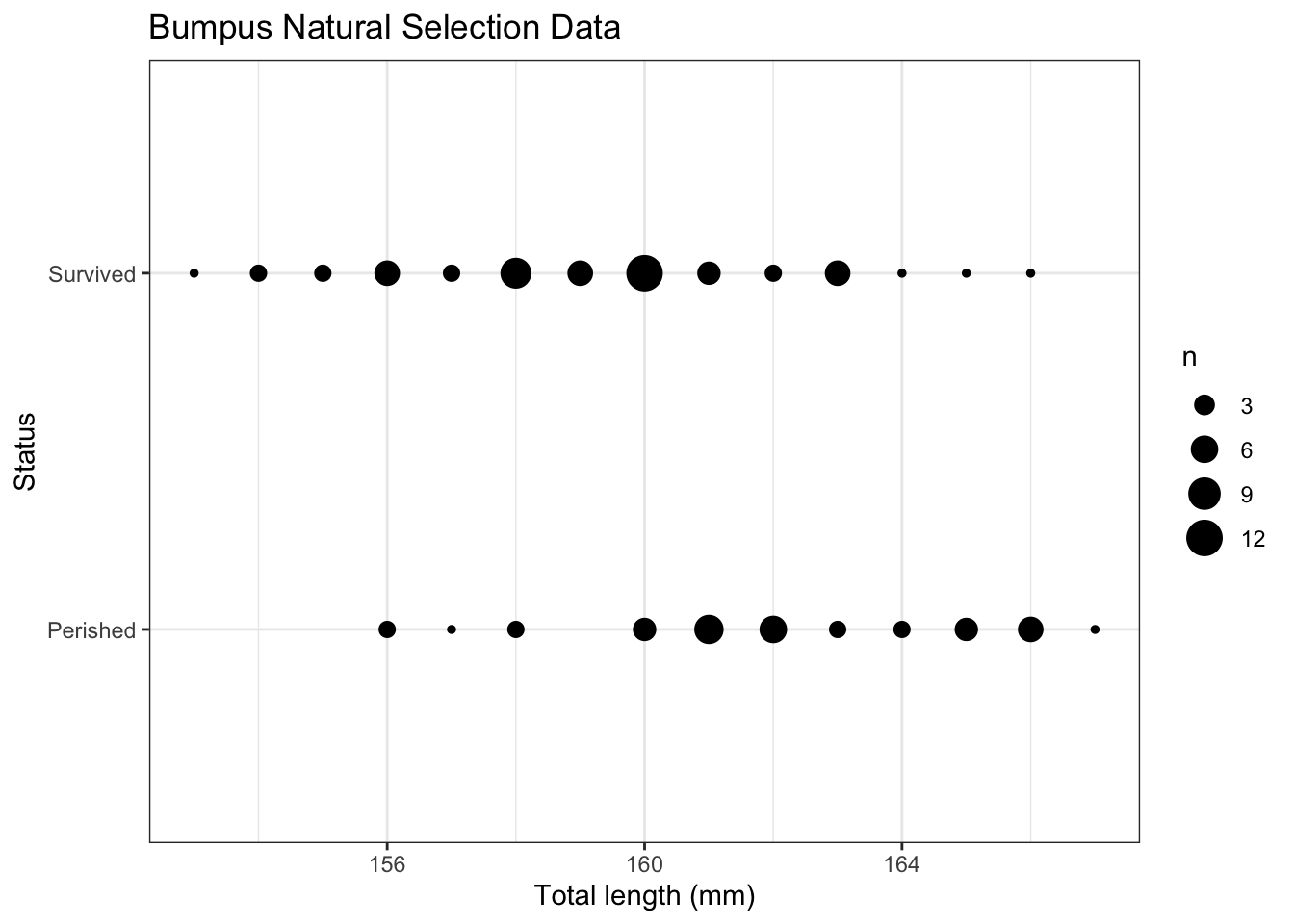
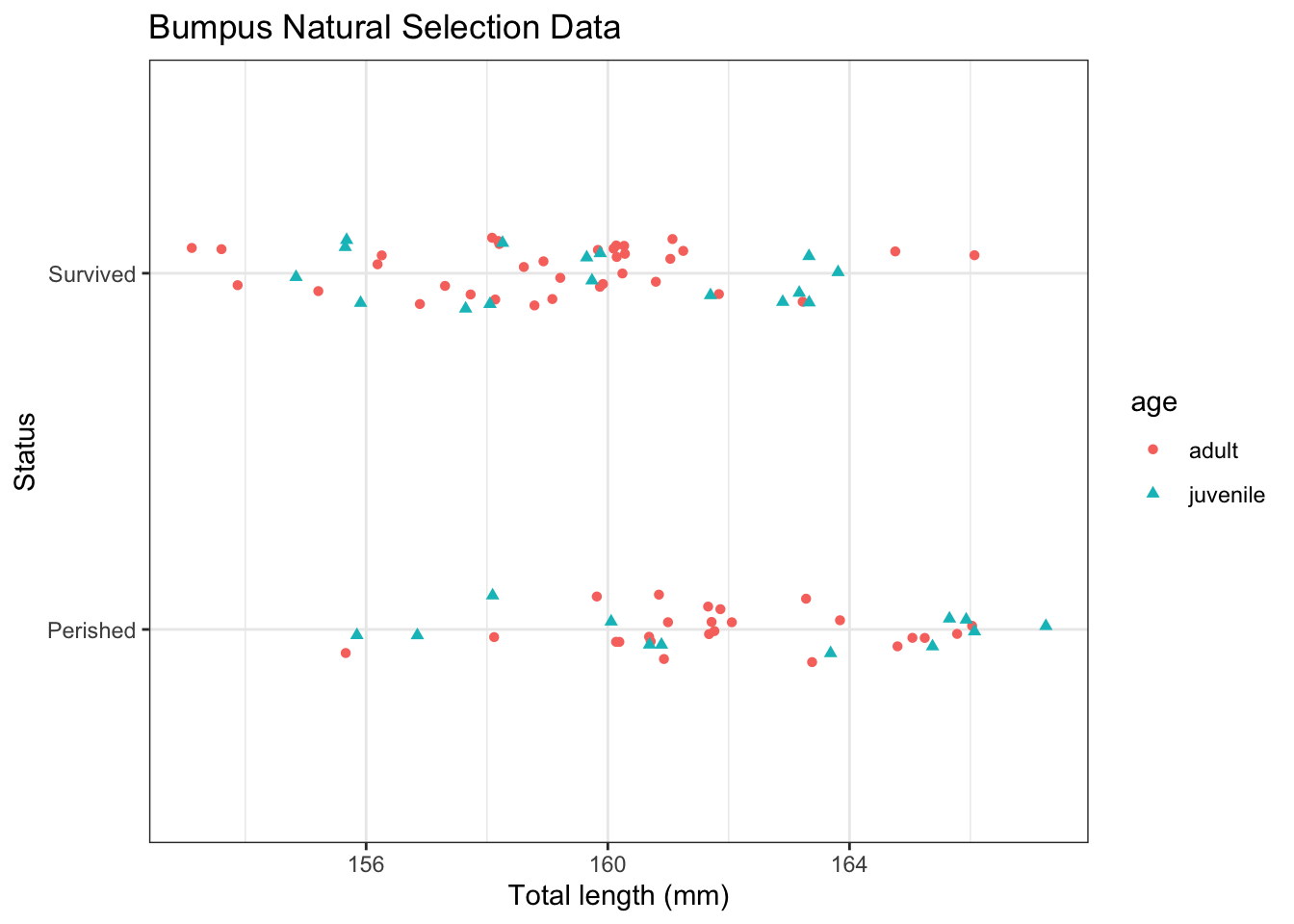
g <-ggplot(d,aes(x = TL,y = Status)) +labs(x ="Total length (mm)",title ="Bumpus Natural Selection Data" ) +geom_point(aes(size = n)) g
When running a logistic regression, you need to decide what success is. This choice is arbitrary, but important to how you interpret the regression. It is a good practice to be explicit about what is success by a numerical vector where 1 represents success and 0 represents failure. Here we will define surviving as success.
# Fit logistic regression when response is binarym <-glm(as.numeric(Status =="Survived") ~# 0 = Perished, 1 = Survived TL, # Explanatory variable(s)data = ex2016,family ="binomial")# Summarysummary(m)
Call:
glm(formula = as.numeric(Status == "Survived") ~ TL, family = "binomial",
data = ex2016)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 54.49312 14.57866 3.738 0.000186 ***
TL -0.33698 0.09062 -3.719 0.000200 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 118.008 on 86 degrees of freedom
Residual deviance: 99.788 on 85 degrees of freedom
AIC: 103.79
Number of Fisher Scoring iterations: 4
# Coefficients m$coefficients
(Intercept) TL
54.4931246 -0.3369782
# Confidence intervalexp(confint(m)[2,]) # multiplicative effect on the odds
Waiting for profiling to be done...
2.5 % 97.5 %
0.5880293 0.8419684
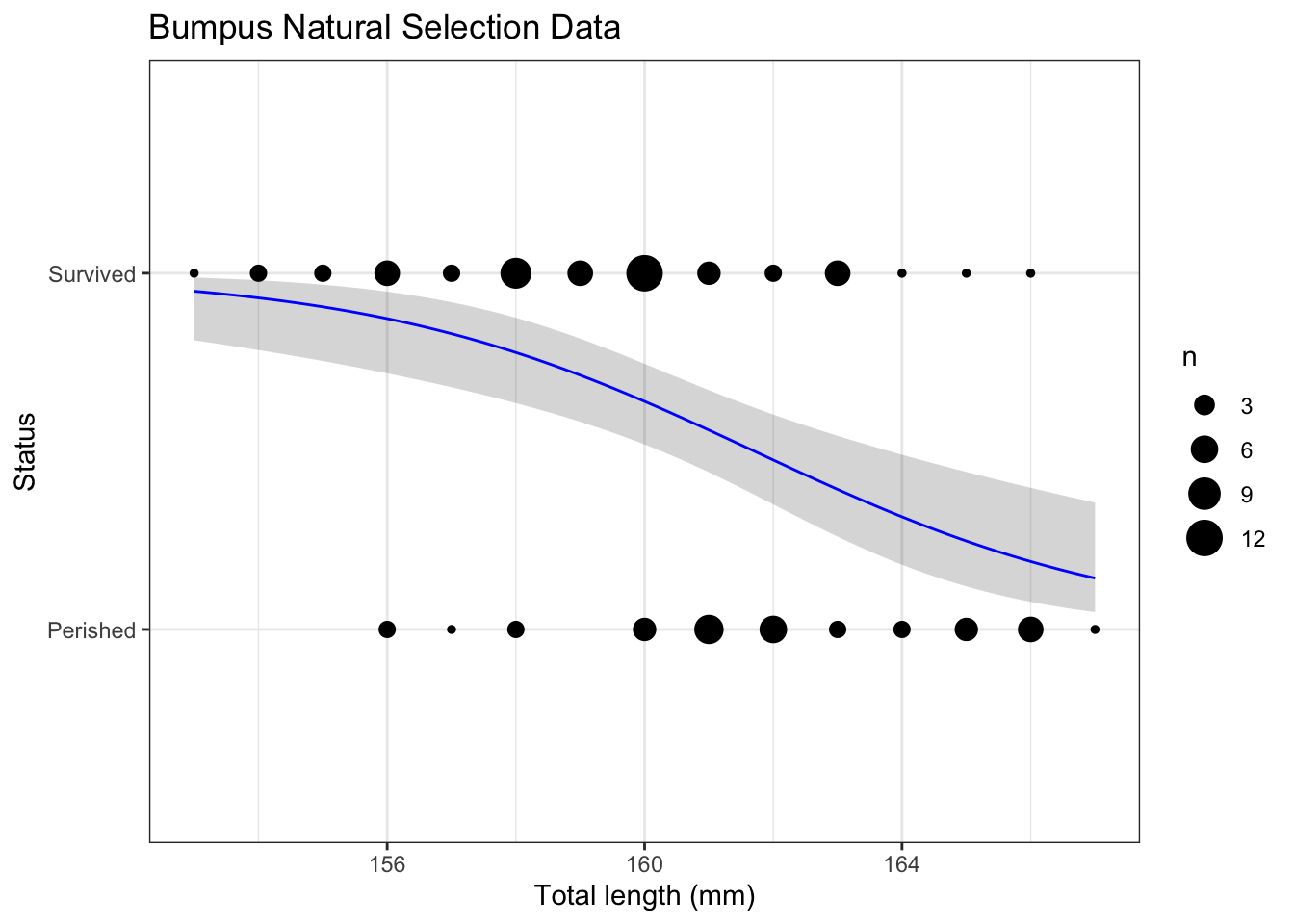
To construct
# Create new datand <-data.frame(TL =seq(from =min(ex2016$TL),to =max(ex2016$TL),length =101 ))# Create predictions and combine with datap <-bind_cols( nd, predict(m, newdata = nd, se.fit =TRUE) |>as.data.frame() |># Manually construct confidence intervalsmutate(lwr = fit -qnorm(0.975) * se.fit,upr = fit +qnorm(0.975) * se.fit,# Expit to get to probability scale# also + 1 so line is within two levels because Perished is 1 and Survived is 2Status =expit(fit) +1,lwr =expit(lwr) +1,upr =expit(upr) +1 ) )# Plotpg <- g +geom_ribbon(data = p,mapping =aes(ymin = lwr,ymax = upr ),alpha =0.2 ) +geom_line(data = p,color ="blue" ) pg
42.2.1 Grouped data
# Group datadg <- d |>pivot_wider(id_cols = TL,names_from = Status,values_from = n,values_fill =0) |># make NAs 0arrange(TL)
To fit the logistic regression with grouped data, we need a matrix where the first column is the successes and the second column is the failures.
# Fit logistic regression with grouped datam2 <-glm(cbind(Survived, # Successes Perished) ~# Failures TL, # Explanatory variable(s)data = dg,family ="binomial")
The two approaches will result in the same answers.
Logistic regression can be used with categorical variables. When both the explanatory variable and response variable are discrete, the data are easily represented in a table.
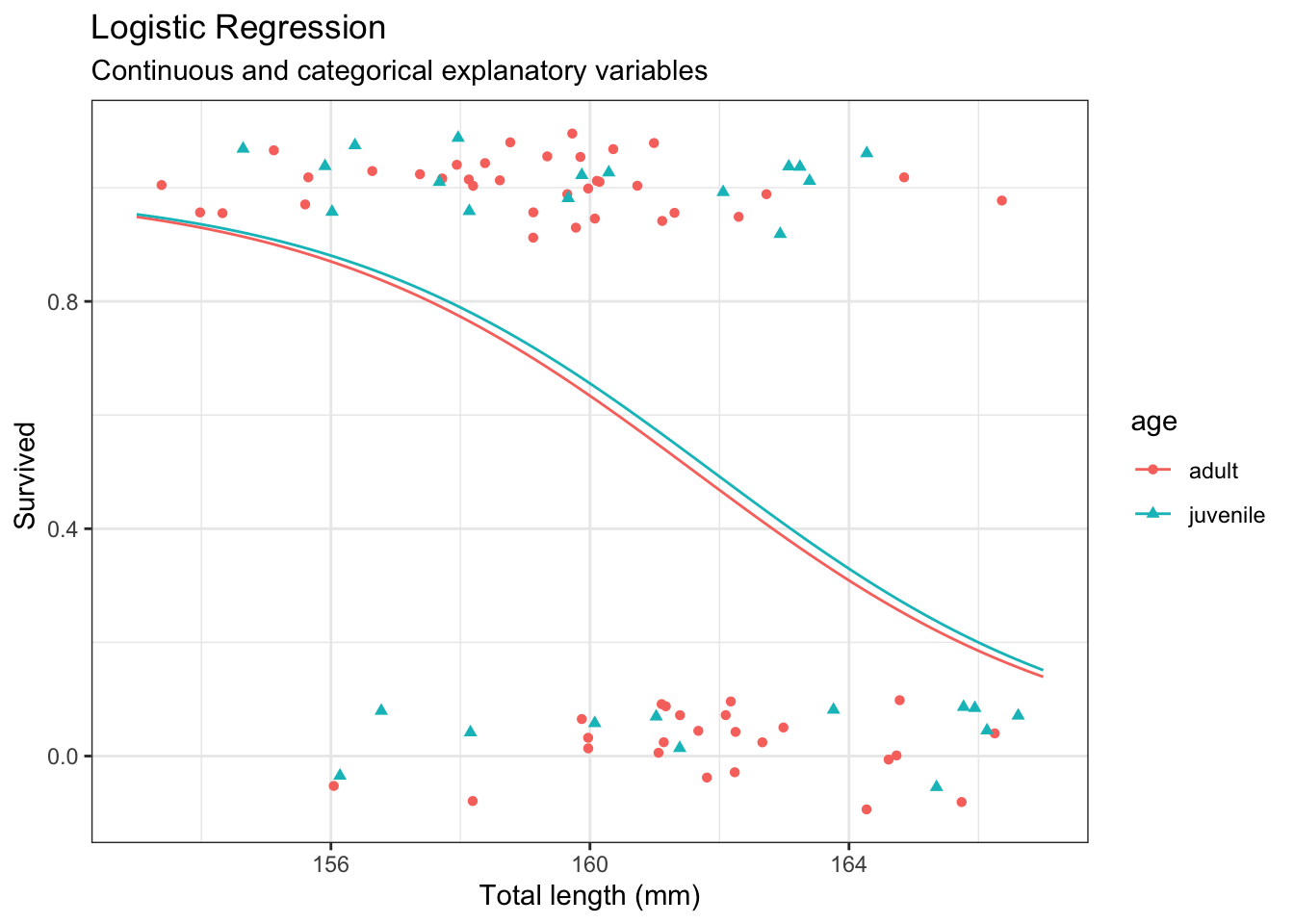
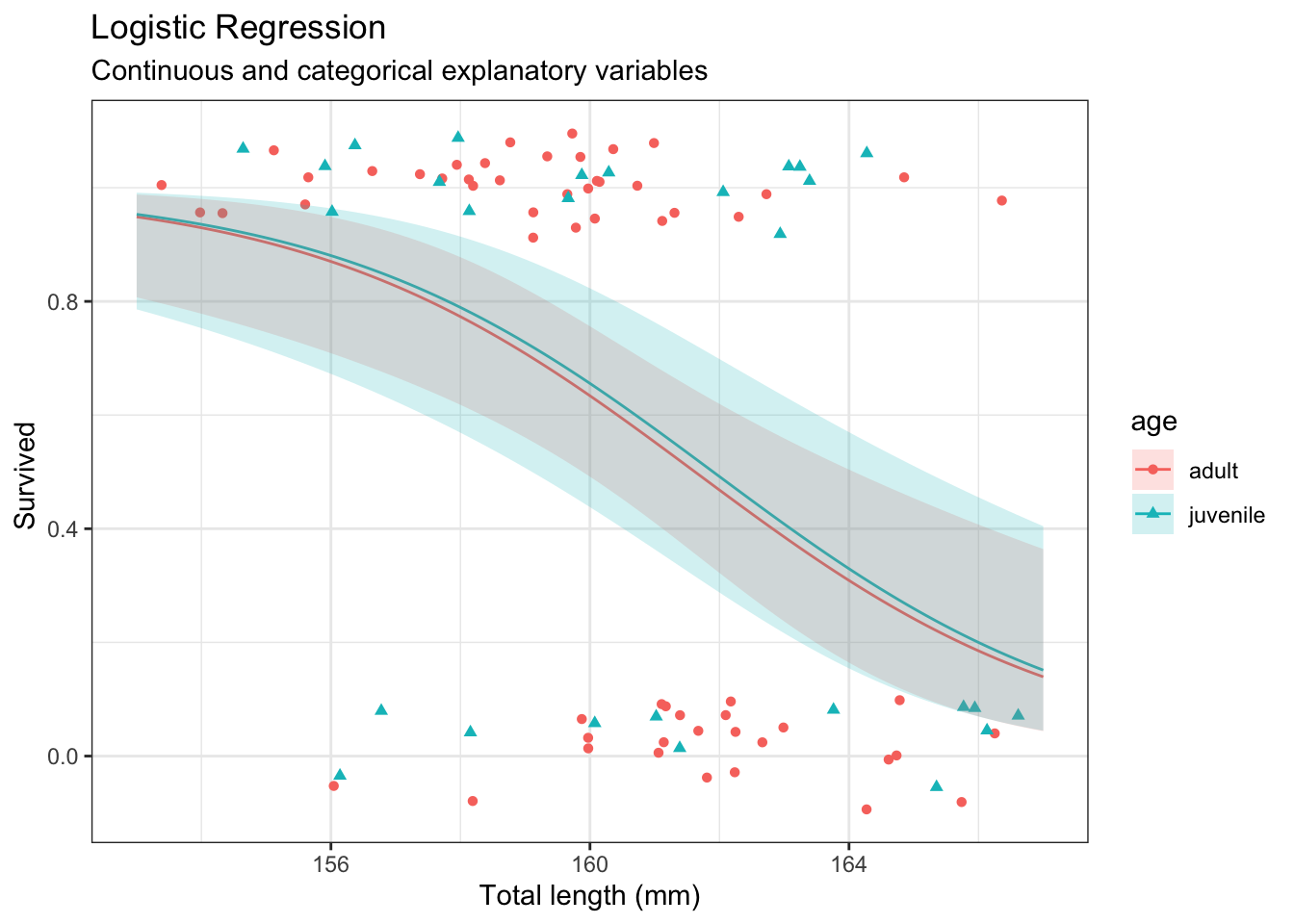
# Create interpretable variablesd <- ex2016 |>mutate(age =ifelse(AG ==1, "adult", "juvenile"),small =ifelse(TL <160, "small", "not small") # this is used later )# Show results in a tabled |>group_by(age) |>summarize(n =n(),p =keep_decimals(sum(Status =="Survived")/n) )
# A tibble: 2 × 3
age n p
<chr> <int> <chr>
1 adult 59 0.59
2 juvenile 28 0.57
Fit logistic regression model using a categorical explanatory variable.
# Fit Logistic regression modelm <-glm(as.numeric(Status =="Survived") ~ age,data = d,family ='binomial')# Model summarysummary(m)
Call:
glm(formula = as.numeric(Status == "Survived") ~ age, family = "binomial",
data = d)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.37729 0.26502 1.424 0.155
agejuvenile -0.08961 0.46483 -0.193 0.847
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 118.01 on 86 degrees of freedom
Residual deviance: 117.97 on 85 degrees of freedom
AIC: 121.97
Number of Fisher Scoring iterations: 4
# Confidence intervalsexp(confint(m)[2,]) # CI for multiplicative effect on the odds (juvenile vs. adult)
Waiting for profiling to be done...
2.5 % 97.5 %
0.3679314 2.3018519
Calculate predictions
# Create data frame with unique explanatory variable valuesnd <- d |>select(age) |>unique()# Predictp <-bind_cols( nd,predict(m,newdata = nd,se.fit =TRUE)|>as.data.frame() |># Manually construct confidence intervalsmutate(lwr = fit -qnorm(0.975) * se.fit,upr = fit +qnorm(0.975) * se.fit,# Expit to get to probability scaleStatus =expit(fit),lwr =expit(lwr),upr =expit(upr) ) )p |>mutate(p =keep_decimals(Status),lwr =keep_decimals(lwr),upr =keep_decimals(upr)) |>select(age, p, lwr, upr)
age p lwr upr
1 adult 0.59 0.46 0.71
60 juvenile 0.57 0.39 0.74
42.4 Two categorical variables
Logistic regression can be used with two categorical variables.
# Data frame for tablet <- d |>group_by(age, small) |>summarize(n =n(),p =sum(Status =="Survived")/n, # survived is 'success'p =keep_decimals(p),.groups ="drop" ) t
# A tibble: 4 × 4
age small n p
<chr> <chr> <int> <chr>
1 adult not small 39 0.44
2 adult small 20 0.90
3 juvenile not small 18 0.50
4 juvenile small 10 0.70
t |>select(-n) |>pivot_wider(id_cols = age,names_from = small,values_from = p )
# A tibble: 2 × 3
age `not small` small
<chr> <chr> <chr>
1 adult 0.44 0.90
2 juvenile 0.50 0.70
A logistic regression model works linearly on the link scale.
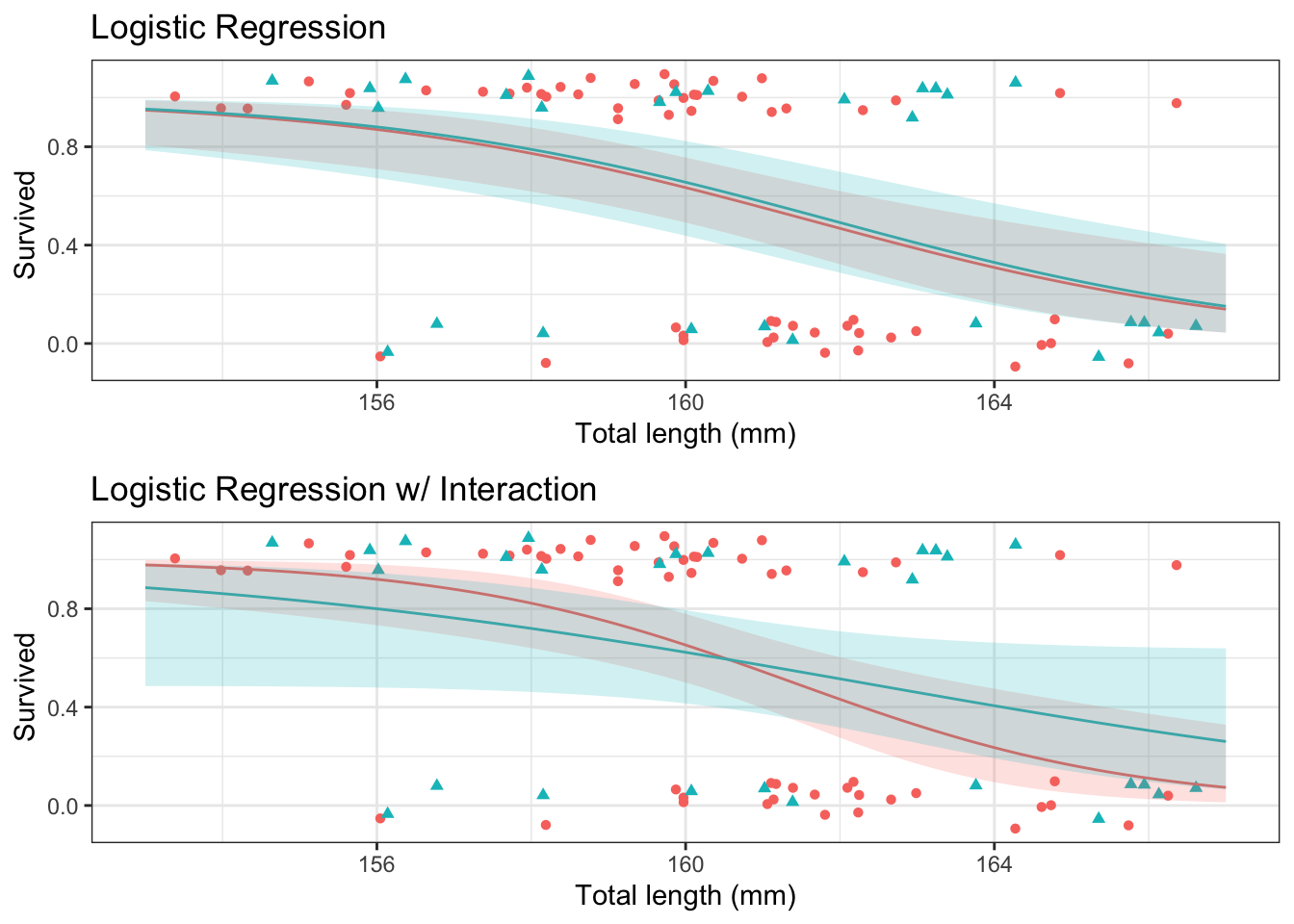
42.4.1 Main effects
Fit main effects regression model
# Fit main effects logistic regression modelm <-glm(as.numeric(Status =="Survived") ~ age + small,data = d,family ='binomial')# Model summarysummary(m)
Call:
glm(formula = as.numeric(Status == "Survived") ~ age + small,
family = "binomial", data = d)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.1330 0.3088 -0.431 0.66664
agejuvenile -0.1364 0.5007 -0.272 0.78524
smallsmall 1.7893 0.5580 3.207 0.00134 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 118.01 on 86 degrees of freedom
Residual deviance: 105.54 on 84 degrees of freedom
AIC: 111.54
Number of Fisher Scoring iterations: 3
# Confidence intervalsexp(confint(m)[2:3,]) # multiplicative effect on the odds
# Create data frame with unique explanatory variable valuesnd <- d |>select(age, small) |>unique()# Predictp <-bind_cols( nd,predict(m,newdata = nd,se.fit =TRUE)|>as.data.frame() |># Manually construct confidence intervalsmutate(lwr = fit -qnorm(0.975) * se.fit,upr = fit +qnorm(0.975) * se.fit,# Expit to get to probability scaleStatus =expit(fit), lwr =expit(lwr),upr =expit(upr) ) )p |>mutate(p =keep_decimals(Status),lwr =keep_decimals(lwr),upr =keep_decimals(upr)) |>select(age, small, p, lwr, upr)
age small p lwr upr
1 adult small 0.84 0.65 0.94
2 adult not small 0.47 0.32 0.62
60 juvenile small 0.82 0.59 0.94
62 juvenile not small 0.43 0.25 0.64
# A tibble: 2 × 3
age small `not small`
<chr> <chr> <chr>
1 adult 0.84 (0.65, 0.94) 0.47 (0.32, 0.62)
2 juvenile 0.82 (0.59, 0.94) 0.43 (0.25, 0.64)
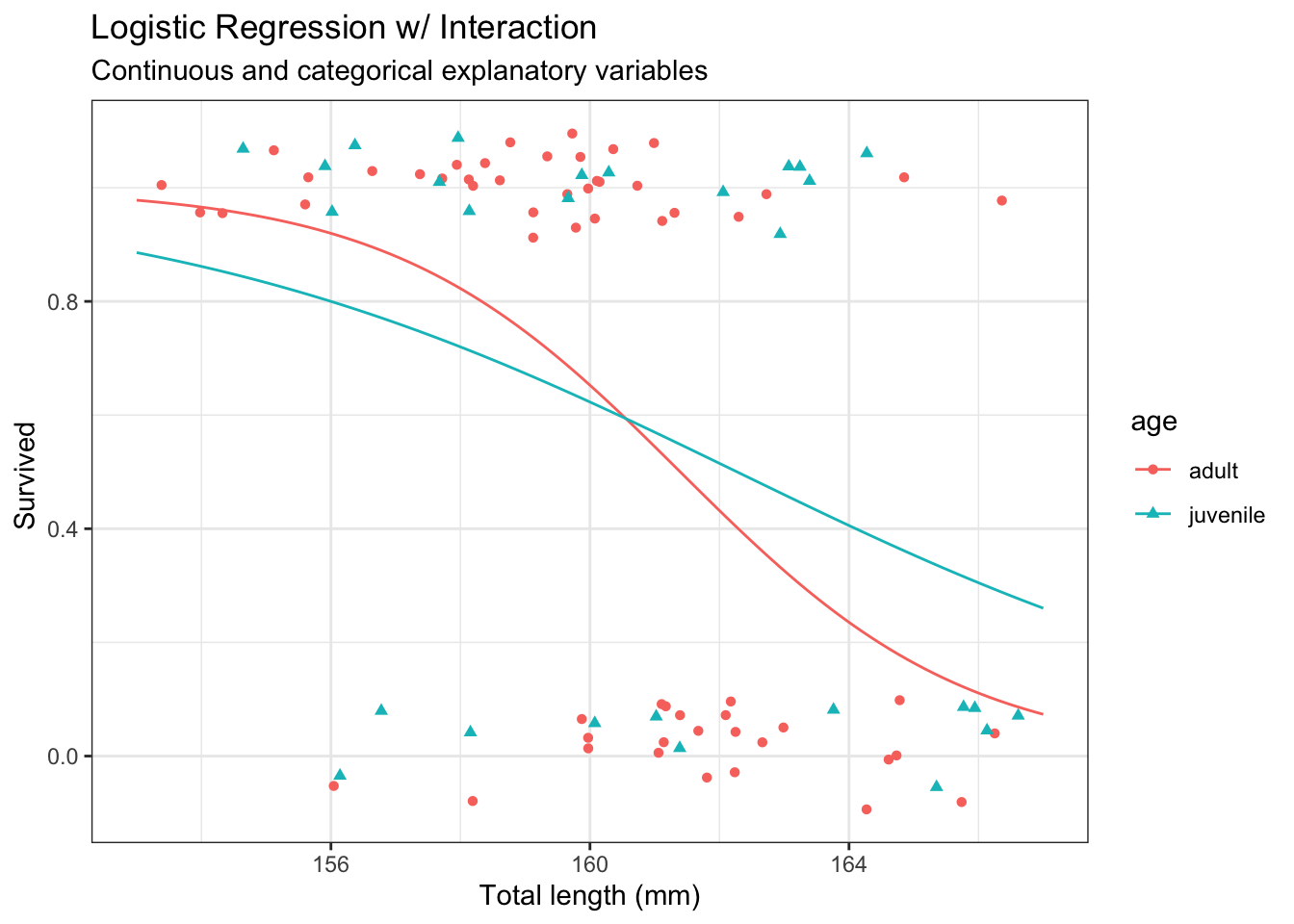
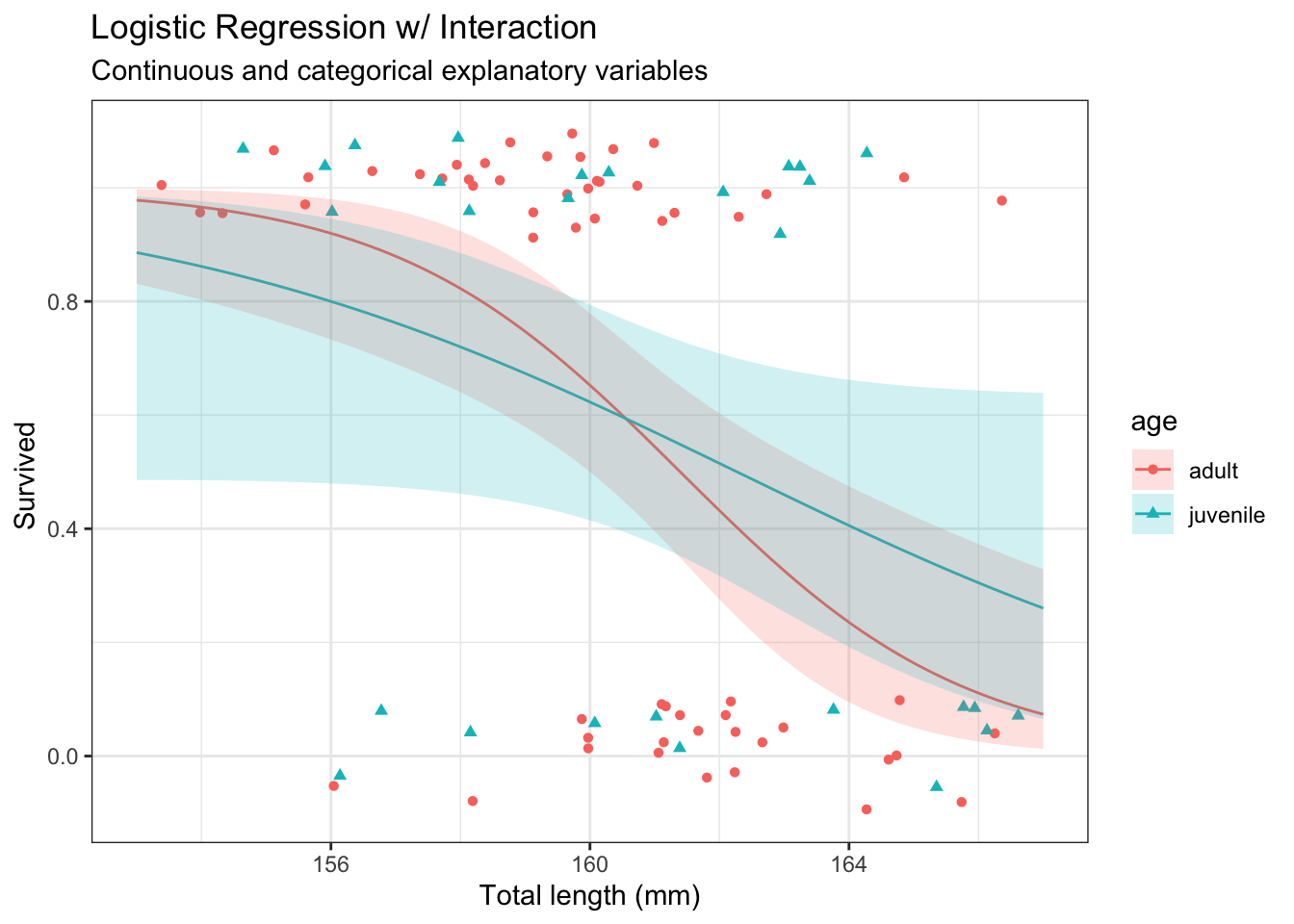
42.4.2 Interaction
Fit interaction regression model
# Fit main effects Poisson regression modelm <-glm(as.numeric(Status =="Survived") ~ age * small,data = d,family ='binomial')# Model summarysummary(m)
Call:
glm(formula = as.numeric(Status == "Survived") ~ age * small,
family = "binomial", data = d)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.2578 0.3229 -0.798 0.42462
agejuvenile 0.2578 0.5714 0.451 0.65183
smallsmall 2.4551 0.8122 3.023 0.00251 **
agejuvenile:smallsmall -1.6078 1.1654 -1.380 0.16772
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 118.01 on 86 degrees of freedom
Residual deviance: 103.60 on 83 degrees of freedom
AIC: 111.6
Number of Fisher Scoring iterations: 4
Calculate predictions
# Predictp <-bind_cols( nd,predict(m,newdata = nd,se.fit =TRUE)|>as.data.frame() |># Manually construct confidence intervalsmutate(lwr = fit -qnorm(0.975) * se.fit,upr = fit +qnorm(0.975) * se.fit,# Expit to get to probability scaleStatus =expit(fit),lwr =expit(lwr),upr =expit(upr) ) )p |>mutate(p =keep_decimals(Status),lwr =keep_decimals(lwr),upr =keep_decimals(upr)) |>select(age, small, p, lwr, upr)
age small p lwr upr
1 adult small 0.90 0.68 0.97
2 adult not small 0.44 0.29 0.59
60 juvenile small 0.70 0.38 0.90
62 juvenile not small 0.50 0.28 0.72
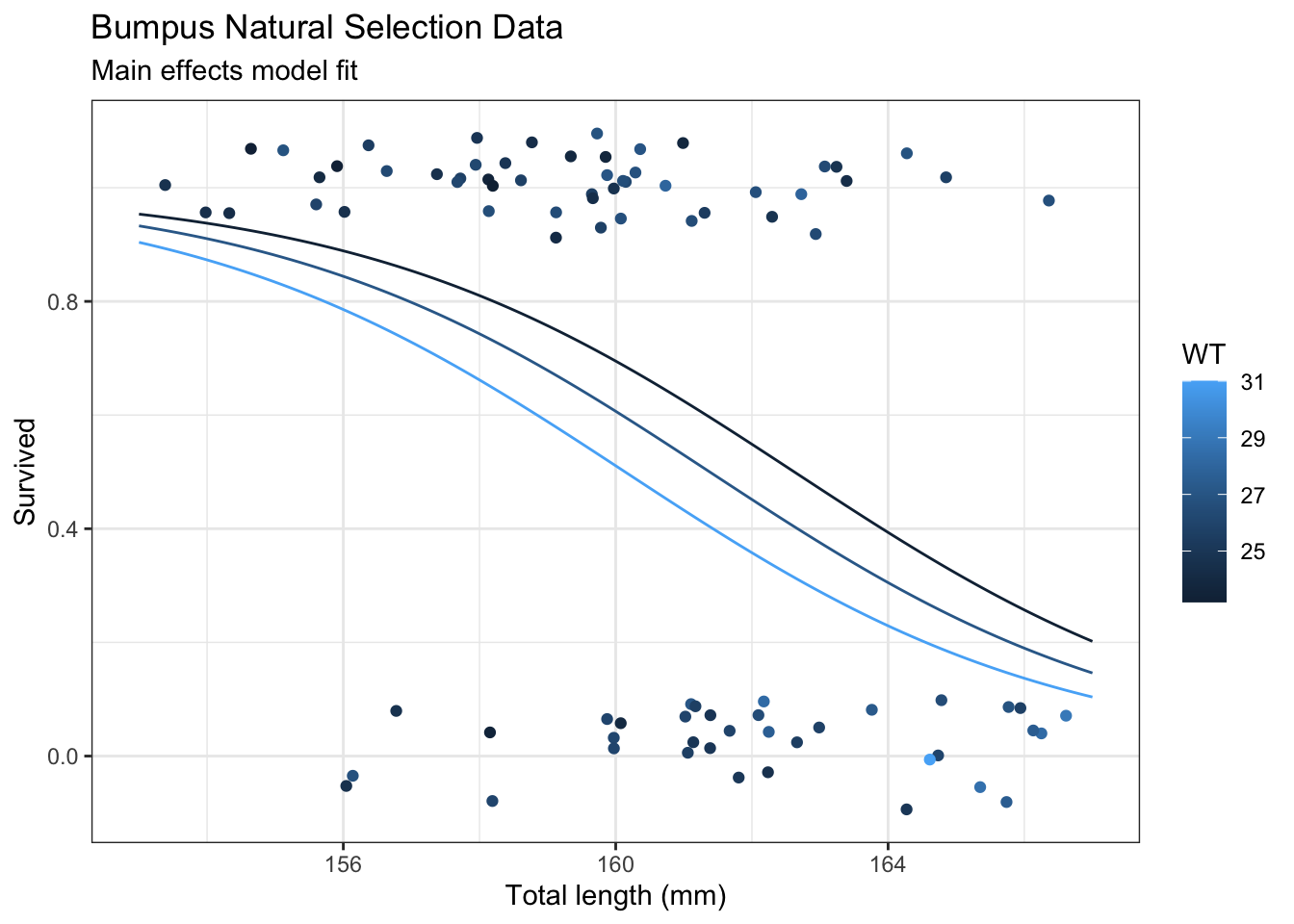
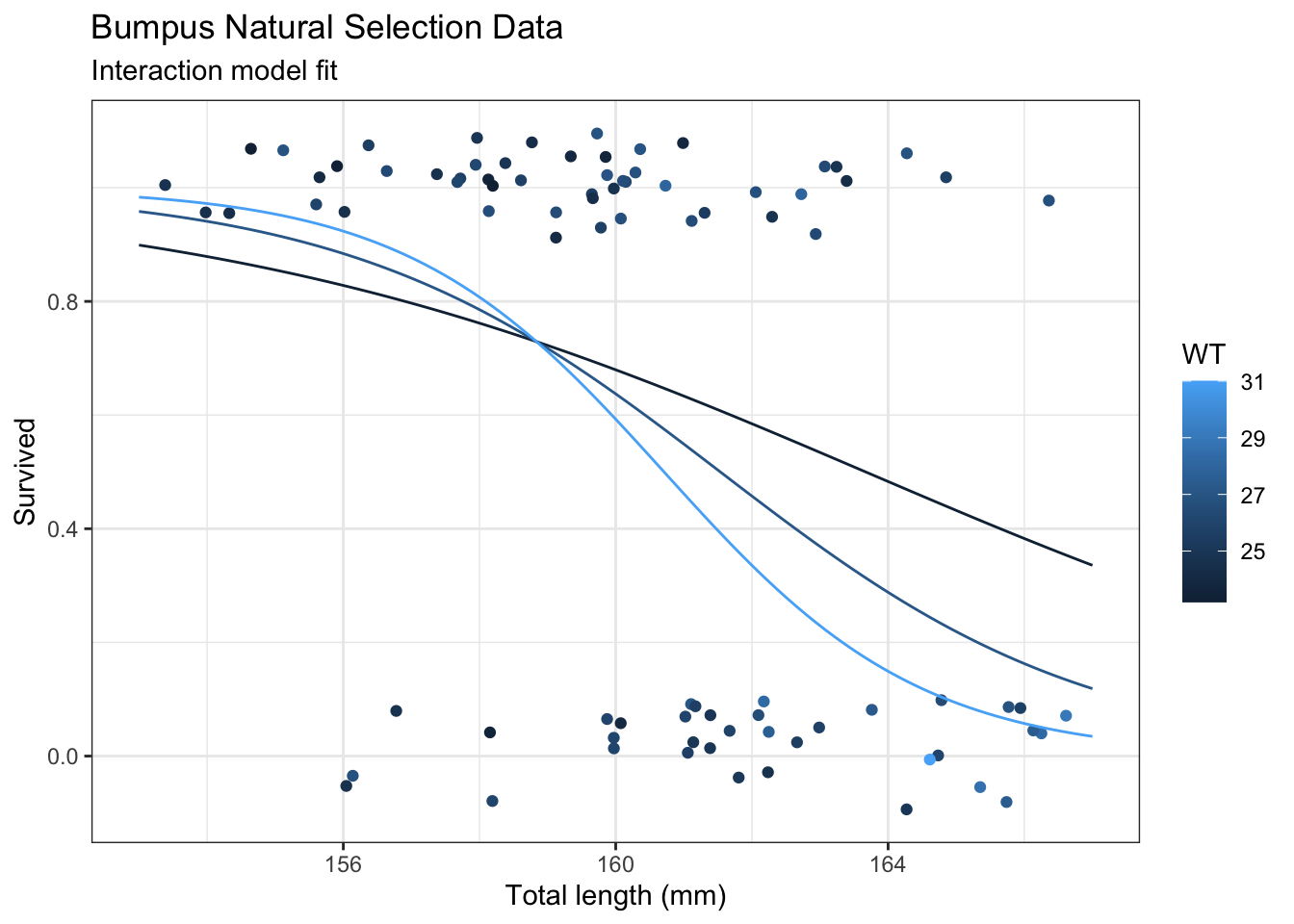
When both explanatory variables are continuous, select certain value of the non-x-axis variable to make lines for.
# Predictionsp <-bind_cols( nd,predict(m,newdata = nd,se.fit =TRUE)|>as.data.frame() |># Manually construct confidence intervalsmutate(lwr = fit -qnorm(0.975) * se.fit,upr = fit +qnorm(0.975) * se.fit,# Exponentiate to get to probability scaleStatus =expit(fit),lwr =expit(lwr),upr =expit(upr) ) )
Plot model predictions
# Plot predictionspg <- g +geom_line(data = p,mapping =aes(y = Status,group = WT )) +labs(subtitle ="Interaction model fit" )pg
42.7 Summary
This chapter introduced logistic regression for a single binary response variable with up to two explanatory variables. The focus of this chapter has been on our ability visualize model fits using ggplot graphics with either geom_smooth or manually creating lines using predict and geom_line.